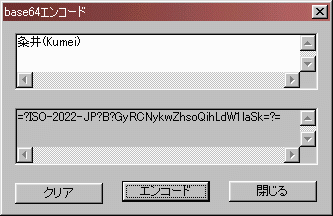
 「エンコード」ボタンを押すとエンコードされます。
エンコードされる文字列が2バイト文字と1バイト文字が混在していても
常に1組の「=?ISO-2022-JP?B?........?=」で表すことにします。
「エンコード」ボタンを押すとエンコードされます。
エンコードされる文字列が2バイト文字と1バイト文字が混在していても
常に1組の「=?ISO-2022-JP?B?........?=」で表すことにします。
 今回はS-JISで書かれたものをbase64でエンコードします。
今回はS-JISで書かれたものをbase64でエンコードします。
「エンコード」ボタンを押すとエンコードされます。
エンコードされる文字列が2バイト文字と1バイト文字が混在していても
常に1組の「=?ISO-2022-JP?B?........?=」で表すことにします。
では、エンコードする方法を考えてみます。
第235章に手動で
エンコードする方法が解説してあります。
これをプログラム化します。
原文をJISに変換した文字列を格納する配列をszOrg,
エンコードしたものを格納する配列をszDestとすると
2.はどのようにすればよいのでしょうか。1.原文をJISに変換する(szOrg) 2.szOrgから6ビットずつに区切る 3.szDestに「=?ISO-2022-JP?B?」をコピー 3.記号に変換して1バイトずつszDestに格納 4.最後にszDestに「?=」を付け加える
szOrgを3バイトずつの組にします。 (szOrg[i], szOrg[i+1], szOrg[i+2])
それぞれを2進で表して(各数字は0または1)
(12345678) (12345678) (12345678)
これを6ビットずつ区切り直すと
(123456) (781234) (567812) (345678)
これらを記号に変換してszDestに格納します。Fを記号に変換する関数とすると
szDest[iR] = F((00123456));
szDest[iR+1] = F((00781234));
szDest[iR + 2] = F((00567812));
szDest[iR + 3] = F((00345678));
とこんな具合になるはずです。
szDest[x]の先頭2ビットは0であることに注意してください。
szDest[iR]はどのように求めればよいのでしょうか。
これは簡単です。szOrg[i]を右に2ビットシフトすればよいですね。
szDest[iR + 1]はszOrg[i]の上位6ビットを0にしてこれを4ビット左シフトしたものに、 szOrg[i + 1]を右に4ビットシフトしたものを足せばよいですね。szDest[iR] = F((szOrg[i]) >> 2);
同様にしてszDest[iR + 2]やszDest[iR + 3]はszDest[iR + 1] = F(((szOrg[i] & 0x3) << 4) + ((szOrg[i + 1]) >> 4));
さて、JISに変換した文字列が常に3の倍数であればよいのですが 当然あまりが出ることもあります。これを考慮してプログラム化するとszDest[iR + 2] = F(((szOrg[i + 1] & 0xf) << 2) + ((szOrg[i + 2]) >> 6)); szDest[iR + 3] = F(szOrg[i + 2] & 0x3f);
とこんな感じになります。convtobaseは記号に変換する関数です。 では、convtobase関数はどうすればよいでしょうか。 これは簡単です。void encode(char *lpszOrg, char *lpszDest) { int i = 0, iR = 16; strcpy(lpszDest, "=?ISO-2022-JP?B?"); while (1) { if (lpszOrg[i] == '\0') { break; } lpszDest[iR] = convtobase((lpszOrg[i]) >> 2); if (lpszOrg[i + 1] == '\0') { lpszDest[iR + 1] = convtobase(((lpszOrg[i] & 0x3) << 4) ); lpszDest[iR + 2] = '='; lpszDest[iR + 3] = '='; lpszDest[iR + 4] = '\0'; break; } lpszDest[iR + 1] = convtobase(((lpszOrg[i] & 0x3) << 4) + ((lpszOrg[i + 1]) >> 4)); if (lpszOrg[i + 2] == '\0') { lpszDest[iR + 2] = convtobase((lpszOrg[i + 1] & 0xf) << 2); lpszDest[iR + 3] = '='; lpszDest[iR + 4] = '\0'; break; } lpszDest[iR + 2] = convtobase(((lpszOrg[i + 1] & 0xf) << 2) + ((lpszOrg[i + 2]) >> 6)); lpszDest[iR + 3] = convtobase(lpszOrg[i + 2] & 0x3f); lpszDest[iR + 4] = '\0'; i += 3; iR += 4; } strcat(lpszDest, "?="); return; }
第235章の変換方法をよく読めばわかります。char convtobase(char c) { if (c <= 0x19) return c + 'A'; if (c >= 0x1a && c <= 0x33) return c - 0x1a + 'a'; if (c >= 0x34 && c <= 0x3d) return c - 0x34 + '0'; if (c == 0x3e) return '+'; if (c == 0x3f) return '/'; return '='; }
では、プログラムを見てみましょう。
メニューに「BASE64エンコード」が増えました。// base6402.rcの一部 ///////////////////////////////////////////////////////////////////////////// // // Menu // MYMENU MENU DISCARDABLE BEGIN POPUP "ファイル(&F)" BEGIN MENUITEM "終了(&X)...", IDM_END END POPUP "オプション(&O)" BEGIN MENUITEM "BASE64デコード(&D)...", IDM_DECODE MENUITEM "BASE64エンコード(&E)...", IDM_ENCODE END END ///////////////////////////////////////////////////////////////////////////// // // Dialog // MYDLG DIALOG DISCARDABLE 0, 0, 201, 135 STYLE DS_MODALFRAME | DS_CENTER | WS_POPUP | WS_CAPTION | WS_SYSMENU CAPTION "BASE64デコード" FONT 9, "MS Pゴシック" BEGIN EDITTEXT IDC_EDIT1,7,7,187,55,ES_MULTILINE | ES_AUTOVSCROLL | ES_AUTOHSCROLL | ES_WANTRETURN | WS_VSCROLL | WS_HSCROLL PUSHBUTTON "デコード",IDC_BUTTON1,72,114,50,14 DEFPUSHBUTTON "クリア",IDOK,15,114,50,14 PUSHBUTTON "閉じる",IDCANCEL,129,114,50,14 EDITTEXT IDC_EDIT2,7,65,187,38,ES_MULTILINE | ES_AUTOVSCROLL | ES_AUTOHSCROLL | ES_READONLY | ES_WANTRETURN | WS_VSCROLL | WS_HSCROLL END MYDLG2 DIALOG DISCARDABLE 0, 0, 187, 127 STYLE DS_MODALFRAME | DS_CENTER | WS_POPUP | WS_CAPTION | WS_SYSMENU CAPTION "base64エンコード" FONT 9, "MS Pゴシック" BEGIN EDITTEXT IDC_EDIT1,7,7,173,38,ES_MULTILINE | ES_AUTOVSCROLL | ES_AUTOHSCROLL | ES_WANTRETURN | WS_VSCROLL | WS_HSCROLL DEFPUSHBUTTON "エンコード",IDOK,68,106,50,14 PUSHBUTTON "クリア",IDC_BUTTON1,7,107,50,14 PUSHBUTTON "閉じる",IDCANCEL,129,106,50,14 EDITTEXT IDC_EDIT2,7,57,173,38,ES_MULTILINE | ES_AUTOVSCROLL | ES_AUTOHSCROLL | ES_READONLY | ES_WANTRETURN | WS_VSCROLL | WS_HSCROLL END
MyEncodeProcのIDOKのところを見てください。lpszOrgなどの 領域を動的に確保しています。lpszOrgはともかくlpszDestは どの位のメモリを確保すればよいのでしょうか。bade64エンコードを すると3バイトの文字列が4バイトに増えます。また、「=?ISO-2022-JP?B?」 などの文字列が付け加わります。さらにJISに変換するときにエスケープ符号列 が加わります。筆者は元の文字列の長さの2倍も確保すれば大丈夫と考えました。 しかし、これではだめなのです。変換前の文字列を1バイトとすると 変換後の文字列を格納するのに2バイト分しかメモリが用意されません。 これでは全然だめですね。// base6402.cpp #ifndef STRICT #define STRICT #endif #include <windows.h> #include <windowsx.h> #include <mbstring.h> #include "resource.h" LRESULT CALLBACK WndProc(HWND, UINT, WPARAM, LPARAM); LRESULT CALLBACK MyDecodeProc(HWND, UINT, WPARAM, LPARAM); LRESULT CALLBACK MyEncodeProc(HWND, UINT, WPARAM, LPARAM); ATOM InitApp(HINSTANCE); BOOL InitInstance(HINSTANCE, int); void decode(char *, char *); char charconv(char); void MyJisToSJis(char *, char *); void GetString(char *, char *); void MySJisToJis(char *, char *); void encode(char *, char *); char convtobase(char); char szClassName[] = "base6402"; //ウィンドウクラス HINSTANCE hInst; int WINAPI WinMain(HINSTANCE hCurInst, HINSTANCE hPrevInst, LPSTR lpsCmdLine, int nCmdShow) { MSG msg; hInst = hCurInst; if (!InitApp(hCurInst)) return FALSE; if (!InitInstance(hCurInst, nCmdShow)) return FALSE; while (GetMessage(&msg, NULL, 0, 0)) { TranslateMessage(&msg); DispatchMessage(&msg); } return msg.wParam; } //ウィンドウ・クラスの登録 ATOM InitApp(HINSTANCE hInst) { WNDCLASSEX wc; wc.cbSize = sizeof(WNDCLASSEX); wc.style = CS_HREDRAW | CS_VREDRAW; wc.lpfnWndProc = WndProc; //プロシージャ名 wc.cbClsExtra = 0; wc.cbWndExtra = 0; wc.hInstance = hInst;//インスタンス wc.hIcon = LoadIcon(NULL, IDI_APPLICATION); wc.hCursor = LoadCursor(NULL, IDC_ARROW); wc.hbrBackground = (HBRUSH)GetStockObject(WHITE_BRUSH); wc.lpszMenuName = "MYMENU"; //メニュー名 wc.lpszClassName = (LPCSTR)szClassName; wc.hIconSm = LoadIcon(NULL, IDI_APPLICATION); return (RegisterClassEx(&wc)); } //ウィンドウの生成 BOOL InitInstance(HINSTANCE hInst, int nCmdShow) { HWND hWnd; hWnd = CreateWindow(szClassName, "猫でもわかるbase64", //タイトルバーにこの名前が表示されます WS_OVERLAPPEDWINDOW, //ウィンドウの種類 CW_USEDEFAULT, //X座標 CW_USEDEFAULT, //Y座標 300, //幅 200, //高さ NULL, //親ウィンドウのハンドル、親を作るときはNULL NULL, //メニューハンドル、クラスメニューを使うときはNULL hInst, //インスタンスハンドル NULL); if (!hWnd) return FALSE; ShowWindow(hWnd, nCmdShow); UpdateWindow(hWnd); return TRUE; } //ウィンドウプロシージャ LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wp, LPARAM lp) { int id; switch (msg) { case WM_COMMAND: switch (LOWORD(wp)) { case IDM_END: SendMessage(hWnd, WM_CLOSE, 0, 0); break; case IDM_DECODE: DialogBox(hInst, "MYDLG", hWnd, (DLGPROC)MyDecodeProc); break; case IDM_ENCODE: DialogBox(hInst, "MYDLG2", hWnd, (DLGPROC)MyEncodeProc); break; } break; case WM_CLOSE: id = MessageBox(hWnd, "終了してもよいですか", "終了確認", MB_YESNO | MB_ICONQUESTION); if (id == IDYES) { DestroyWindow(hWnd); } break; case WM_DESTROY: PostQuitMessage(0); break; default: return (DefWindowProc(hWnd, msg, wp, lp)); } return 0; } LRESULT CALLBACK MyDecodeProc(HWND hDlg, UINT msg, WPARAM wp, LPARAM lp) { static HWND hEdit1, hEdit2; int len; HGLOBAL hMem, hMem2; char *lpszOrg, *lpszResult; switch (msg) { case WM_INITDIALOG: hEdit1 = GetDlgItem(hDlg, IDC_EDIT1); hEdit2 = GetDlgItem(hDlg, IDC_EDIT2); return TRUE; case WM_COMMAND: switch (LOWORD(wp)) { case IDCANCEL: EndDialog(hDlg, IDCANCEL); return TRUE; case IDOK: Edit_SetText(hEdit1, ""); Edit_SetText(hEdit2, ""); return TRUE; case IDC_BUTTON1: len = GetWindowTextLength(hEdit1); hMem = GlobalAlloc(GHND, len + 1); lpszOrg = (char *)GlobalLock(hMem); hMem2 = GlobalAlloc(GHND, len + 1); lpszResult = (char *)GlobalLock(hMem2); if (lpszOrg == NULL || lpszResult == NULL) { MessageBox(hDlg, "メモリ確保に失敗", "Error", MB_OK); return TRUE; } Edit_GetText(hEdit1, lpszOrg, len + 1); GetString(lpszOrg, lpszResult); Edit_SetText(hEdit2, lpszResult); GlobalUnlock(hMem2); GlobalFree(hMem2); GlobalUnlock(hMem); GlobalFree(hMem); return TRUE; } return FALSE; } return FALSE; } void decode(char *lpszStr, char *lpszResult) { int len, i, iR; char a1, a2, a3, a4; len = strlen(lpszStr); i = 0; iR = 0; while (1) { if (i >= len) break; a1 = charconv(lpszStr[i]); a2 = charconv(lpszStr[i+1]); a3 = charconv(lpszStr[i+2]); a4 = charconv(lpszStr[i+3]); lpszResult[iR] = (a1 << 2) + (a2 >>4); lpszResult[iR + 1] = (a2 << 4) + (a3 >>2); lpszResult[iR + 2] = (a3 << 6) + a4; i += 4; iR += 3; } return; } char charconv(char c) { char str[256]; if (c >= 'A' && c <= 'Z') return (c - 'A'); if (c >= 'a' && c <= 'z') return (c - 'a' + 0x1a); if (c >= '0' && c <= '9') return (c - '0' + 0x34); if (c == '+') return 0x3e; if (c == '/') return 0x3f; if (c == '=') return '\0'; wsprintf(str, "不正な文字[%c]を検出しました", c); MessageBox(NULL, str, "Error", MB_OK); return '\0'; } void MyJisToSJis(char *lpOrg, char *lpDest) { int i = 0, iR = 0, c; BOOL bSTART = FALSE;//JIS->SJIS変換が必要かどうか while (1) { if (lpOrg[i] == 0x1b && lpOrg[i + 1] == 0x24 && lpOrg[i + 2] == 0x42 || lpOrg[i] == 0x1b && lpOrg[i + 1] == 0x24 && lpOrg[i + 2] == 0x40) { bSTART = TRUE; i += 3; continue; } if (lpOrg[i] == 0x1b && lpOrg[i + 1] == 0x28 && lpOrg[i + 2] == 0x42 || lpOrg[i] == 0x1b && lpOrg[i + 1] == 0x28 && lpOrg[i + 2] == 0x4a) { bSTART = FALSE; i += 3; continue; } if (lpOrg[i] >= 0x21 && lpOrg[i] <= 0x7e && bSTART) { c = MAKEWORD(lpOrg[i + 1], lpOrg[i]); lpDest[iR] = (char)HIBYTE(_mbcjistojms(c)); lpDest[iR + 1] = (char)LOBYTE(_mbcjistojms(c)); i += 2; iR += 2; continue; } if (i == 0 && lpOrg[0] == '\n') { lpDest[iR] = '\r'; lpDest[iR + 1] = '\n'; i++; iR += 2; continue; } if (lpOrg[i] == '\n' && lpOrg[i - 1] != '\r') { lpDest[iR] = '\r'; lpDest[iR + 1] = '\n'; i++; iR += 2; continue; } if (lpOrg[i] == '=') { i++; continue; } if (lpOrg[i] == '\0') { lpDest[iR] = lpOrg[i]; break; } lpDest[iR] = lpOrg[i]; iR++; i++; } return; } void GetString(char *szOrg, char *szResult) { char *token; char szBuf[1024], szBuf2[1024]; int len, mod; BOOL bCopy = TRUE; //?をコピーしてよいか token = strtok(szOrg, "=\r\n\t"); while (token != NULL) { if (strstr(token, "?ISO-2022-JP?B?") != token && strstr(token, "?iso-2022-jp?B?") != token) { if (strcmp(token, "?") != 0 && bCopy == TRUE) { MyJisToSJis(token, szBuf); strcat(szResult, szBuf); } } else { strcpy(szBuf, token + 15); if (szBuf[strlen(szBuf) - 1] == '?') szBuf[strlen(szBuf) - 1] = '='; len = strlen(szBuf); mod = len % 4; switch (mod) { case 1: strcat(szBuf, "==="); bCopy = FALSE; break; case 2: strcat(szBuf, "=="); bCopy = FALSE; break; case 3: strcat(szBuf, "="); bCopy = FALSE; break; } decode(szBuf, szBuf2); MyJisToSJis(szBuf2, szBuf); strcat(szResult, szBuf); } bCopy = TRUE; token = strtok(NULL, "=\r\n\t"); } return; } LRESULT CALLBACK MyEncodeProc(HWND hDlg, UINT msg, WPARAM wp, LPARAM lp) { static HWND hEdit1, hEdit2; char *lpszOrg, *lpszBuf, *lpszDest; HGLOBAL hMemOrg, hMemBuf, hMemDest; int len; switch (msg) { case WM_INITDIALOG: hEdit1 = GetDlgItem(hDlg, IDC_EDIT1); hEdit2 = GetDlgItem(hDlg, IDC_EDIT2); return TRUE; case WM_COMMAND: switch (LOWORD(wp)) { case IDOK: len = GetWindowTextLength(hEdit1); hMemOrg = GlobalAlloc(GHND, len + 1); lpszOrg = (char *)GlobalLock(hMemOrg); hMemBuf = GlobalAlloc(GHND, (len + 1) * 2 + 50); lpszBuf = (char *)GlobalLock(hMemBuf); hMemDest = GlobalAlloc(GHND, (len + 1) * 2 + 50); lpszDest = (char *)GlobalLock(hMemDest); if (lpszOrg == NULL || lpszBuf == NULL || lpszDest == NULL) { MessageBox(hDlg, "メモリ確保に失敗しました", "Error", MB_OK); return TRUE; } Edit_GetText(hEdit1, lpszOrg, (len + 1)); MySJisToJis(lpszOrg, lpszBuf); encode(lpszBuf, lpszDest); Edit_SetText(hEdit2, lpszDest); GlobalUnlock(hMemOrg); GlobalFree(hMemOrg); GlobalUnlock(hMemBuf); GlobalFree(hMemBuf); GlobalUnlock(hMemDest); GlobalFree(hMemDest); return TRUE; case IDCANCEL: EndDialog(hDlg, IDCANCEL); return TRUE; case IDC_BUTTON1: Edit_SetText(hEdit1, ""); Edit_SetText(hEdit2, ""); return TRUE; } return FALSE; } return FALSE; } void MySJisToJis(char *lpszOrg, char *lpszDest) { int i = 0, iR = 0, c; BOOL bSTART = FALSE; while (1) { if (_ismbblead(lpszOrg[i]) && bSTART == FALSE) { lpszDest[iR] = 0x1b; lpszDest[iR + 1] = 0x24; lpszDest[iR + 2] = 0x42; c = MAKEWORD(lpszOrg[i + 1], lpszOrg[i]); lpszDest[iR + 3] = (char)HIBYTE(_mbcjmstojis(c)); lpszDest[iR + 4] = (char)LOBYTE(_mbcjmstojis(c)); bSTART = TRUE; i += 2; iR += 5; if (!_ismbblead(lpszOrg[i])) { lpszDest[iR] = 0x1b; lpszDest[iR + 1] = 0x28; lpszDest[iR + 2] = 0x42; bSTART = FALSE; iR += 3; } continue; } if (_ismbblead(lpszOrg[i]) && bSTART) { c = MAKEWORD(lpszOrg[i + 1], lpszOrg[i]); lpszDest[iR] = (char)HIBYTE(_mbcjmstojis(c)); lpszDest[iR + 1] = (char)LOBYTE(_mbcjmstojis(c)); i += 2; iR += 2; if (!_ismbblead(lpszOrg[i])) { lpszDest[iR] = 0x1b; lpszDest[iR + 1] = 0x28; lpszDest[iR + 2] = 0x42; bSTART = FALSE; iR += 3; } continue; } if (lpszOrg[i] == '\r') { lpszDest[iR] = '\n'; i += 2; iR++; continue; } if (lpszOrg[i] == '\0') { lpszDest[iR] = lpszOrg[i]; break; } lpszDest[iR] = lpszOrg[i]; iR++; i++; } return; } void encode(char *lpszOrg, char *lpszDest) { int i = 0, iR = 16; strcpy(lpszDest, "=?ISO-2022-JP?B?"); while (1) { if (lpszOrg[i] == '\0') { break; } lpszDest[iR] = convtobase((lpszOrg[i]) >> 2); if (lpszOrg[i + 1] == '\0') { lpszDest[iR + 1] = convtobase(((lpszOrg[i] & 0x3) << 4) ); lpszDest[iR + 2] = '='; lpszDest[iR + 3] = '='; lpszDest[iR + 4] = '\0'; break; } lpszDest[iR + 1] = convtobase(((lpszOrg[i] & 0x3) << 4) + ((lpszOrg[i + 1]) >> 4)); if (lpszOrg[i + 2] == '\0') { lpszDest[iR + 2] = convtobase((lpszOrg[i + 1] & 0xf) << 2); lpszDest[iR + 3] = '='; lpszDest[iR + 4] = '\0'; break; } lpszDest[iR + 2] = convtobase(((lpszOrg[i + 1] & 0xf) << 2) + ((lpszOrg[i + 2]) >> 6)); lpszDest[iR + 3] = convtobase(lpszOrg[i + 2] & 0x3f); lpszDest[iR + 4] = '\0'; i += 3; iR += 4; } strcat(lpszDest, "?="); return; } char convtobase(char c) { if (c <= 0x19) return c + 'A'; if (c >= 0x1a && c <= 0x33) return c - 0x1a + 'a'; if (c >= 0x34 && c <= 0x3d) return c - 0x34 + '0'; if (c == 0x3e) return '+'; if (c == 0x3f) return '/'; return '='; }
base64のエンコードとデコードがわかったら、またメールのプログラムを 改良できますね。
Update 30/Oct/1999 By Y.Kumei